
Hi, this talk is about geodata and CouchDB. In order to understand why CouchDB is great for geodata, you need to understand how CouchDB works.

Forget everything what you know about relational databases. CouchDB is different, it’s an so-called document oriented database. CouchDB isn’t meant to be a general replacement for relational databases, it is just a better solution for some of your problems (probably even most of your problems).
But let’s get started with the most basic aspect: Documents. They are like a record in a database, a single entry. This is the way CouchDB stores the actual data.

Take the following example. It’s a weather station which measures rainfall and temperature once a day. Don’t care about the attributes with a leading underscore at the top, these are CouchDB internals. The actual data is below. It’s quite self-explanatory.
People that are used to get their data into the third normal form will probably start to cry when they look at this document. Every day the location and the state will be stored again. But that is perfectly fine for CouchDB.
Those documents consist of key-value pairs (it’s JSON) and they are schema free.

But what does “schema free” mean?
It means that you don’t need to think to much upfront about what your data will be structured like. You don’t need to think about relations or what might be needed for the future. You just put the data as it currently is into the database and in case it changes, you just change the documents.
For example if you attach a new sensor to your weather station.

For example if you attach a new sensor for atmospheric pressure to your weather station…

…you simply add it to the document. That’s all.
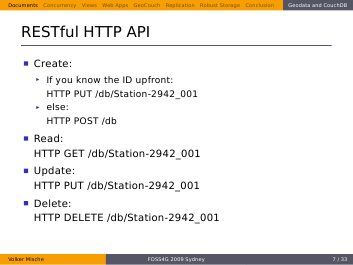
Documents want to be stored and retrieved from the database. CouchDB supports the four basic database functions create, read, update and delete via a RESTful HTTP API.
Read and delete are easy to understand, but what about create and update. It looks strange that they both use a PUT request. If a document doesn’t exist yet, you simply put it with a certain ID and it gets created.
To understand how updating works, I need to explain CouchDB’s concurrency first.

CouchDB is highly concurrent. It can serve a high number of parallel requests. On the one hand this is rooted in the utilisation of the Erlang programming language and thus the Erlang virtual machine, on the other hand it is achieved through “Multiversion concurrency control”. Read accesses are never blocked, writers a serialized. To understand MVCC a bit better let’s have a closer look at the update mechanism.

When I was talking about the structure of a Document there were two fields for CouchDB internal usage. One of them was named “_rev”. It changes whenever the document is updated.
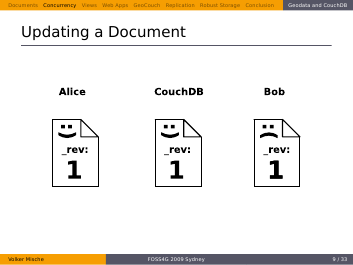
This document with the smiley is in the database. Now two people want to update it in parallel, it’s Alice and Bob.
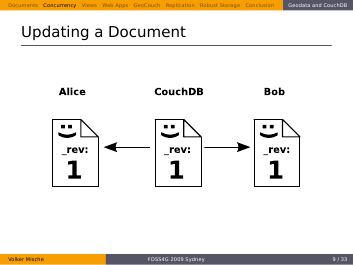
They both don’t know about each other and request the document at the same time.
Now Bob updates the document…
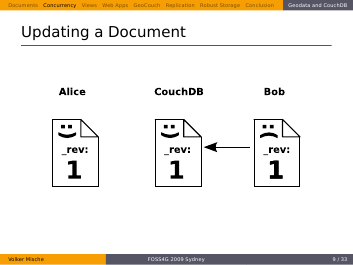
…and sends it back to the server. The revisions need to match in order to update the Document successfully. But they obviously do.

Therefore the Document in the CouchDB database was updated with Bob’s version and the revision was updated as well.
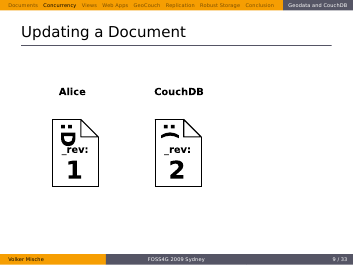
Now Alice updates her Document…
…and sends it back to the server.
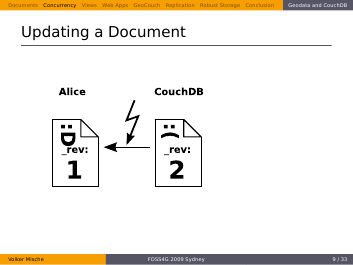
But this time the revisions don’t match. She gets a conflict back.
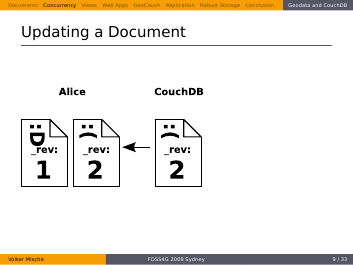
What she does now is requesting the current revision of the Document, so that she can resolve the conflict herself.
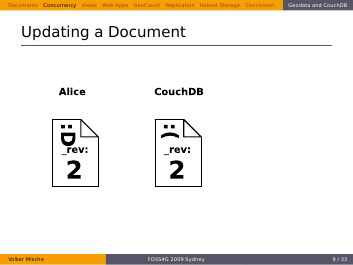
She still likes her changes more than Bob’s ones.
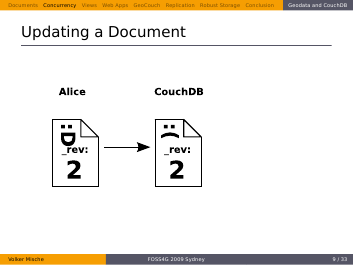
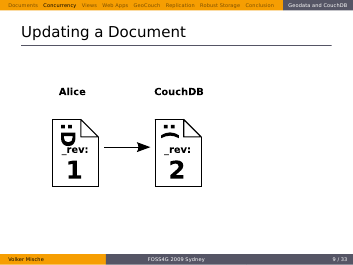
So she tries to send her updated Document back to the server, this time with a matching revision.
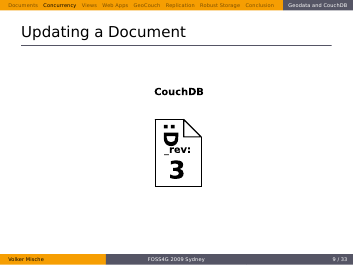
Finally the document is updated in the database and again the revision changes, too.
I’ve told you how to store and retrieve single document, but how do you get more data out of CouchDB. The answer is Views.

The query system of CouchDB is based on the MapReduce paradigm. If you haven’t heard of MapReduce before, don’t be scared, it is easy to grasp. Though the next few slides are rather for the geeks in the audience who’d like to know how to work with CouchDB.
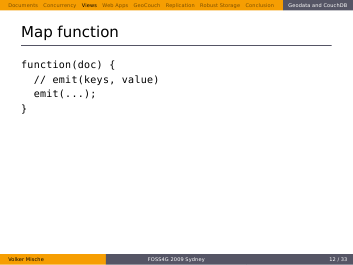
This is the basic structure of a map function, it’s written in JavaScript. A document is passed in as function parameter, the resulting output is made with the emit function call which takes two parameters, the keys and a value. A concrete example should make it a bit clearer. Do you remember the data about the weather station? We like to output the measured rainfall of a station.
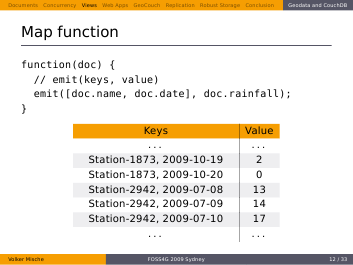
You can see that the keys are composed of the station name and the date. Hence, the results are sorted first by the name of the station, then by date. The value only contains the rainfall. If you would like to output more than just the rainfall, you could replace the “doc.temperature” with any arbitrary JSON (or even the whole Document). Of course the keys could be different as well, but those serve well for our purpose.
The result of such a View is like a static list of key-value pairs, one pair for every Document. This list will be updated whenever documents changes (respectively when they are added or get deleted). This is called incremental MapReduce.

Accessing such a view is done with a simple GET. You can see the URL at the top. This would return the temperatures from all dates of all stations. The result is like a static list of key-value pairs, one pair per Document.
But you don’t need the full list all the time, you definitely want to restrict the results.
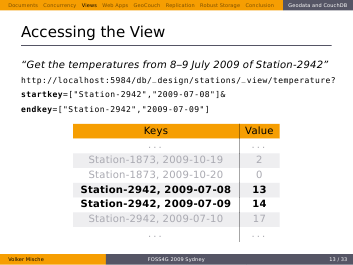
That’s easy, just take a slice out of the view. For example if you want to “Get all temperatures from 8--9 July 2009 of Station-2942”, you simply add a start- and an endkey parameter to the URL that contains the keys of the slice boundaries.

That was the map of MapReduce, now it’s time for the reduce. Reduce, as the name implies, is there to reduce the results of the map function to some smaller output. I won’t go into much detail here, but just show a basic example.

This looks complicated, but it actually isn’t. It’s enough to say that the values function parameter contains the output of the map function. We loop through it, add the values up and finally return the sum.
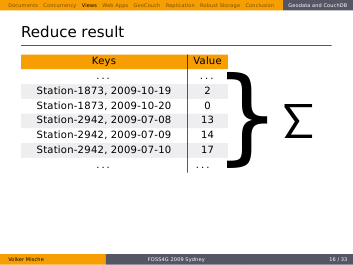
Let’s take the map function we are familiar with already and apply this reduce function to it.
We get the sum of all values, this means all stations with all dates. But we want a single station only. As before we can select a range…
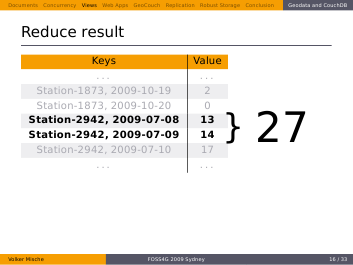
…and get the expected result we were looking for.

All this can be easily done with a relational database, too, so you might wonder: why you should use CouchDB instead? One reason might be when you are building web mapping applications.
The most prominent one is probably Google maps, followed by the ultimate free (as in freedom) alternative OpenStreetMap.
A common use-case is serving up your own data with the previously mentioned mapping services as base maps. I’m sure many people from the audience either have needed or have build such a mapping application themselves.
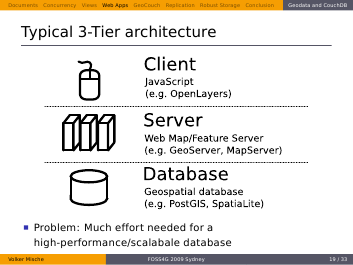
The current setup for serving up you data on top of those base maps looks something like that. A typical 3-Tier architecture.
A (geospatial) database at the bottom, above as middleware, the web map server that serves up the data, and at the top of it the client library that runs in the browser that requests the data and the base map tiles.
A problem is often the creation of a well performing database. After normalising your data nicely into tables, you might need to start to denormalise them in some way to gain more performance. This, again, can be a quite time consuming process. That’s why I think CouchDB is the answer to that problem.
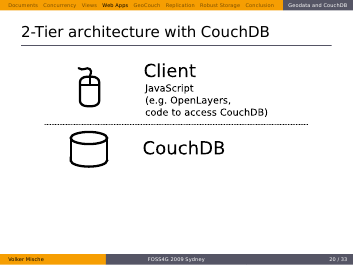
With CouchDB the architecture gets simpler. You just have CouchDB at the server-side, and JavaScript on the client side which requests the data from CouchDB’s RESTful HTTP API. There’s no need for a middleware to serve up features.
That sounds great, but as I’ve mentioned before Views are like a static list of key-vale pairs, how could you perform things like bounding box or polygon searches? The answer is: GeoCouch.
GeoCouch is a spatial extension for CouchDB to allow spatial queries. The goal is to be for CouchDB what PostGIS is for PostgreSQL.
Currently it needs a spatial database as a backend. SpatiaLite is supported at the moment, but PostGIS would be easy to add. Now you probably wonder: “why should I use a relational spatial database in conjunction with CouchDB when I could use it without CouchDB as well”.
The reason is the seamless integration with CouchDB. You don’t need to put any effort in keeping the spatial index in sync with your CouchDB. It’s automatically done whenever a document changes. So you will still have all the advantages CouchDB has, like MapReduce, the robust storage or the easy replication which I’ll talk about later.

GeoCouch currently supports all major geometry types as defined by the OGC. Points, LineStrings and Polygons and the multi variants.
The supported queries go largely along the lines of the OpenSearch geo extension draft. Bounding box, polygon and radius search.

If you use GeoCouch your architecture might look something like that. It’s still 2-tier, but you have an automatically synchronised spatial index next to CouchDB.

It’s time to move on to another important core feature of CouchDB. The replication. You can have crazy setups with it, but I will just mention a few of them that seem to be the most important ones for every day use.

With CouchDB, you can have several masters that are synchronise with each other. Think about offices spread all over that world. Everyone can add or edit data on his node, and get it synchronized with other nodes easily. Even if the Internet goes down, you could replicate your changes later on.
Or to simplify the work of an admin in cases where you have an infrastructure with several deployment stages. You could make changes to a later stage and replicate it down to an earlier stage (as well as up of course).
Another point is “work ‘offline’, synchronize later”. Take your local CouchDB with you on your mobile device, collect some data outside on the field, and replicate it back to your master server at home.
The replication works so well, that it will be used in Ubuntu Karmic, that’s the next Ubuntu stable version which is about to be released, to synchronise bookmarks and contacts between your computers.

CouchDB’s robust storage is ideal to serve as a massive storage system. You can have several gigabyte of data in one CouchDB without running into troubles. But the important thing is the robustness. Systems can go down for several reasons, for example a power breakdown. For most systems a corrupted file is either the end of the story, or it needs a recovery tool. But CouchDB…

…is always in a consistent state. If a file gets corrupted, it would use the previous state. Therefore there’s no…
…shutdown command. You just kill the process. This works because of the way CouchDB stores the data. Every database is a single file which grows over time. The data structure is called…
… Append-only B-Tree. Data gets written only to the end of a file. Nothing is overwritten. Even if you delete a document the information that it got deleted will be stored at the end of the file. Hence it is easy to go back to a consistent state as mentioned before. As the file grows over time, you sometimes want to get rid of the old, no longer needed information. That is what…
…compaction is for. This is basically an operation where the current state of the B-Tree gets rewritten into a new one without the information of previous operations.

CouchDB does not only support documents in JSON format, but you can also attach binary files to those documents. You might have read it on my blog. I’ve written a small CouchDB backend for Metacarta’s TileCache. On the one hand it was amazing how easy it was. On the other hand it opens a lot of possibilities. E.g. storing a history of the tiles, or flag tiles as dirty, so that they get rerendered.
But a far better idea is to use it as a storage for metadata and optionally the data itself as well. The most prominent Open Source implementation of a metadata server is probably GeoNetwork. In my opinion CouchDB would ideal as a next generation replacement of GeoNetwork. Especially there the robustness and the easy replication is an important thing.

CouchDB is a perfect fit for robust, highly concurrent systems. It eases the development significantly and therefore reduces costs with its schema free Documents and its RESTful API. Easy replication is good for cloud computing as well as the outlined “take it offline” approach for mobile devices.
CouchDB has a future and won’t vanish soon, as it is an Apache Top Level Project with a nice and active community. Additionally it used in production systems e.g. at the BBC. Furthermore CouchDB’s user base will grow rapidly as it is soon to be used in the most popular Linux Desktop Distribution Ubuntu.
The geodata market is heavily growing and the requirements are changing quickly. New solutions should be considered and CouchDB is definitely a candidate for your next-generation spatial data infrastructure as a geodata storage.

